How AI Models Think: The Latest Reasoning Techniques in LLMs (2025)
Large Language Models (LLMs) are getting better at “thinking things through.” Instead of jumping straight to an answer, modern LLMs can work through problems step by step, consider alternatives, take actions like looking up information, and even reflect on their own mistakes. Researchers have developed several novel prompting and training techniques to enhance these reasoning abilities. In this article, we’ll explore the most cutting-edge reasoning techniques as of 2025 – what they are, how they work, simple examples of each, where they shine, and which models or companies are using them. We’ll cover:
- Chain-of-Thought prompting (CoT) – teaching models to “think step by step.”
- Tree-of-Thought (ToT) – exploring multiple reasoning paths like branches of a tree.
- ReAct (Reason + Act) – combining reasoning with actions in an environment.
- Reflexion – letting the model iteratively reflect and improve on its answers.
- Chain-of-Action-Thought (CoAT) – a new approach with special “meta-actions” for self-reflection and strategy changes.
- Flow-of-Options (FoO) – a structured method to consider diverse solution options and overcome biased thinking.
- Other emerging techniques – like self-consistency and self-questioning, which further push LLM reasoning to new heights.
Whether you’re a tech enthusiast or a researcher, this tour will demystify how today’s AI models reason through complex tasks, using analogies and examples along the way. Let’s dive in.
Chain-of-Thought Prompting (CoT)
Chain-of-Thought (CoT) prompting is a foundational technique that got LLMs to start “thinking out loud.” Instead of forcing a model to produce an answer in one go, CoT prompts it to generate a sequence of intermediate reasoning steps before giving the final answer. In essence, the model is guided to solve a problem step by step, much like a person writing down their working on paper.
How it Works: When using CoT, we provide either explicit instructions or exemplars that encourage the model to break a task into parts. For example, an explicit CoT prompt might say, “Let’s think step by step,” prompting the model to output a chain of reasoning. Alternatively, implicit CoT involves giving a few examples of solved problems with their reasoning; the model then imitates that logical process on new questions. The key is that the model produces a logical trail of thoughts (a “chain”) that ideally leads to the correct answer.
Simple Example: Imagine asking a model: “If a bakery has 18 cupcakes, then bakes 12 more, and sells 15, how many are left?” Without CoT, a model might hastily respond “15” with no explanation, which could be a guess. With chain-of-thought prompting, the model will reason it out explicitly: “They started with 18. Baked 12 more, that makes 30. Then sold 15, so 30 - 15 = 15 remain.” It then gives the answer 15. This step-by-step reasoning is exactly what CoT enables. By articulating each step, the model is less likely to make a mistake on multi-step problems, and the process is more transparent.
Why It’s Useful: CoT prompting has dramatically improved accuracy on tasks that require multi-step reasoning – math word problems, logic puzzles, commonsense reasoning, and so on. By tackling one step at a time, the model avoids the pitfall of trying to do everything in its head at once. The chain-of-thought acts like scratch paper or a thought process. In complex domains (finance calculations, legal reasoning, etc.), this leads to more coherent and correct outputs rather than unexplained answers. In fact, experiments have shown that even very large models can fail at certain math problems if they answer directly, but succeed with near perfect accuracy when CoT prompting is used.
Who’s Using It: Chain-of-thought prompting was introduced by Google researchers in 2022, and it quickly became a go-to technique across the industry. OpenAI has adopted CoT-like methods in their advanced models – according to one source, CoT is “the primary technique used” in OpenAI’s reasoning models, allowing them to “think before they answer” and achieve high scores on math and science benchmarks. For example, by using internal chain-of-thought reasoning, a model in the GPT-series ranked in the 89th percentile on Codeforces programming problems and among the top 500 in a national math Olympiad qualifier – performance that rivals expert humans. Many other AI labs and companies (Anthropic’s Claude, Google’s PaLM, etc.) utilize chain-of-thought prompting or fine-tune their models on chain-of-thought data to enhance reasoning. In open-source, projects like the Humanloop and LangChain communities encourage CoT for building better AI assistants.
Limitations & Enhancements: Chain-of-thought is powerful, but it can still go wrong if the model’s “thoughts” veer off track. One interesting enhancement is self-consistency decoding – instead of trusting a single chain of thought, the model generates many possible chains and then takes a kind of majority vote on the final answer. This self-consistency approach dramatically boosts accuracy by choosing the answer that the most reasoning paths agree on. For instance, self-consistency improved a model’s math word problem performance by 17.9% on the GSM8K benchmark compared to standard CoT. Essentially, it’s like checking the work by solving the problem in different ways and seeing which answer comes up most often – further reducing errors. Even so, CoT by itself laid the groundwork: once models learned to articulate reasoning, a whole new world of more advanced techniques (as we’ll see next) became possible.
Tree-of-Thought (ToT) Prompting
Chain-of-thought is linear – one step after another – but what if a model could explore multiple lines of thought simultaneously, like considering different approaches to a problem? This is the idea behind Tree-of-Thought (ToT) prompting (sometimes called “Tree-of-Thoughts” in research). ToT extends the chain-of-thought concept into a branching tree of possibilities.
What It Is: In Tree-of-Thought prompting, the model doesn’t commit to a single chain of reasoning. Instead, at each step it can branch out into different potential “thoughts” or actions, forming a tree-like search of the solution space. The model can then evaluate partial solutions, backtrack from dead-ends, and choose the most promising branch to follow next – much like how you might plan several ways to solve a puzzle and then pursue the one that looks best.
How It Works: Think of ToT as an algorithmic search over the model’s thought process. The procedure often goes like this:
- 1. Generate multiple thoughts for a step: Instead of one next step, the model generates several possible continuations (branching out). For example, if solving a puzzle, it might propose two or three different next moves or hypotheses.
- 2. Evaluate or prune: These branches are evaluated – sometimes using the model’s own judgment or a heuristic – to see which seem promising. The model might have a mechanism to rate intermediate states or check consistency with the goal. Unpromising branches can be pruned (discarded).
- 3. Advance down the branches: For the promising options, the model expands them further by generating the next step(s) from those states, growing the tree deeper.
- 4. Lookahead and backtracking: The model can simulate a few steps down a branch (“lookahead”) to foresee where it might lead. If it leads to a wrong answer or contradiction, the model can backtrack and try a different branch. This prevents getting stuck on a single flawed line of reasoning.
- 5. Solution selection: If one branch reaches a correct or satisfactory solution, the process can stop there. Or, if multiple complete solutions are found, the model can pick the best. In some implementations, a final answer is chosen by comparing all the completed branches (similar to the self-consistency idea, but across branches of a tree).
In essence, Tree-of-Thought turns reasoning into a search problem, where the model explores a space of possible thought paths rather than following one trajectory blindly.
Analogy: Imagine you’re solving a maze. A chain-of-thought approach is like walking through the maze following one path until you hit a dead end (then you fail) or reach the exit. A tree-of-thought approach is like standing above the maze, considering multiple paths at each junction (“I could go left or right here... let’s see where each might lead”) and tracing out those paths in advance. You can abandon the paths that hit walls and focus on the one that leads to the exit. This ability to plan, explore, and backtrack is what ToT gives an LLM.
Who’s Behind It: Tree-of-Thought prompting was introduced in 2023 by AI researchers (including teams from Princeton and Google). The official code was open-sourced by the Princeton NLP group, sparking a lot of experimentation in the community. While it’s a research-stage technique, companies like IBM have noted its potential: ToT “mirrors how a model can expand on a prompt by generating increasingly specific details, similar to a tree structure” and allows the model to “explore multiple branches before committing to a path”. In practice, ToT can be implemented on top of APIs like GPT-4 by orchestrating the prompting process (toolkits like LangChain or TSAR have toy implementations that build a tree of model queries). We haven’t yet seen a public-facing product explicitly called “Tree-of-Thought” mode, but the technique is influencing how advanced systems are built. It’s likely a glimpse of how tomorrow’s AI will reason – more like chess players planning many moves ahead rather than just reacting step by step.
Use Cases: Beyond puzzles and games, ToT could assist in creative tasks (e.g. brainstorming multiple plot options for a story and then continuing the best one), complex question answering (considering different angles or explanations), or optimization problems (exploring different solution strategies). It’s essentially tree search meets LLM. That said, ToT is more computationally intensive since it requires multiple runs of the model to build the tree. So it may be used selectively when linear CoT is not enough. In 2025, ToT remains cutting-edge and an active research area into how to best guide the branching and evaluation of thoughts.
ReAct (Reason + Act)
One limitation of both CoT and ToT is that the model is still just thinking in text without interacting with anything external. But what if a reasoning process requires looking up information or taking some action in the world (like clicking a button or querying a database)? Enter ReAct, which stands for Reason + Act. The ReAct paradigm allows an LLM to think and act in tandem, interleaving reasoning steps with actions that affect an external environment.
What It Is: ReAct is a framework where the model produces two kinds of outputs: thoughts (reasoning traces) and actions. An action could be calling an API, doing a web search, moving an agent in a game, or any operation outside the model’s internal thought. After an action, the model receives an observation (the result of that action) which it can then reason about, and the cycle continues. This loop continues until the model decides it has enough information to conclude with an answer or final output.
How It Works: The prompting for ReAct typically involves giving the model a specific format. For example, we might prompt it with a few-shot example like:
- Thought 1: “Hmm, the question asks for X, I should probably look up Y first.”
- Action 1: “Search(Y)” (This instructs a search tool)
- Observation 1: “…(some result from the search)….”
- Thought 2: “The result suggests Z. Next, I need to calculate W from Z.”
- Action 2: “Calculator(Z to W)”
- Observation 2: “W = 42.”
- Thought 3: “Now I have what I need. I can answer the question.”
- Answer: “42.”
This thought→action→observation loop enables the model to dynamically gather information and adjust its plan. In a way, the chain-of-thought is no longer isolated; it’s augmented by the ability to act on the world (even if “the world” is just a set of tools we provide, like search, calculators, databases, etc.).
Simple Analogy: Think of an AI agent solving a murder mystery. A pure chain-of-thought model might internally deduce who the culprit is just from the clues it was given, but it can’t physically check anything. A ReAct-based agent, however, could reason “I should inspect the crime scene for fingerprints,” then perform an action InspectCrimeScene, receive a clue as observation, reason further “The fingerprint matches the butler’s,” then decide on the answer “It was the butler.” The reasoning and acting inform each other in a loop, much like how a human detective alternates between theorizing and gathering evidence.
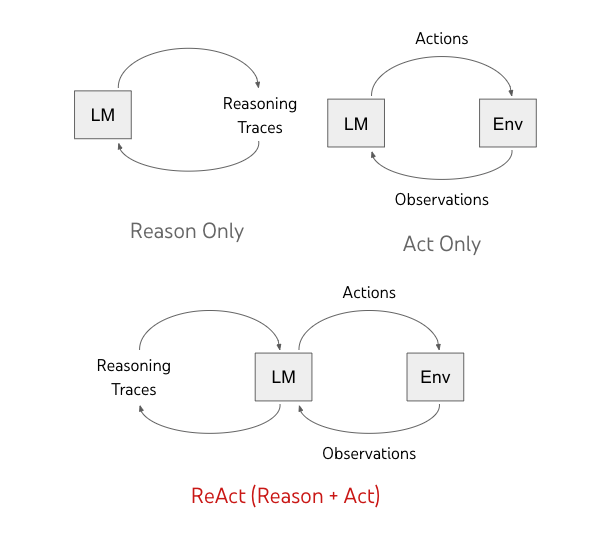
Figure: Illustration of the ReAct paradigm: Top-left shows a model that only reasons (thinking in a loop with itself), top-right shows a model that only acts (taking actions in an environment without long-term planning), and bottom shows ReAct, where the language model (LM) alternates between reasoning traces and actions that affect an external environment (Env), using observations to inform further reasoning
Why It’s Useful: ReAct unlocks a whole new set of capabilities for LLMs. With reasoning alone, a model is limited to the knowledge in its parameters and cannot perform real-time operations. By incorporating actions, the model can fetch new information (e.g. search the web or query a knowledge base), use tools (like a calculator, translator, or code interpreter), or interact in a simulated environment (like moving in a text-based game or controlling a robot). The reasoning part ensures that these actions are taken in a sensible, goal-directed way (the model “figures out” what it needs to do next), rather than randomly trying things. This synergy means the model is much better at decision making tasks. In fact, researchers demonstrated that ReAct prompting “systematically outperforms reasoning-only or acting-only paradigms” on a variety of tasks. It makes the model’s behavior more interpretable and controllable, since you can see its thought process and the rationale behind each action. For example, in a web browsing task, a ReAct agent will show you something like: Thought: “The question is about population of Paris. I should search the web.” → Action: Search("Paris population") → Obs: “Paris population is 2.1 million (2020).” → Thought: “Now I have the data, I can answer.” → Answer: “About 2.1 million.” This is both transparent and effective, as the agent was able to get the info it needed in real time instead of relying on potentially outdated training data.
Use Cases: The ReAct technique is at the core of many AI agent systems today. OpenAI’s ChatGPT Plugins and tools use a similar approach – the model reasons about when to invoke a plugin (e.g. a web browser or calculator) and then uses it, observes the result, and continues. Similarly, frameworks like LangChain explicitly implement ReAct-style prompting to let GPT-4 call functions. Google’s research team, who introduced ReAct in late 2022, showed it being useful in tasks like text-based game playing and web navigation, where an agent needs both reasoning and action. Essentially, ReAct turns an LLM into an interactive problem solver rather than a static question answerer.
Many current AI assistants behind the scenes use this pattern. For instance, AutoGPT-style systems (autonomous GPT-4 agents) rely on ReAct-like loops to decide on actions such as file operations or API calls. Microsoft’s Jarvis (an early demo of tool-using GPT) was also built on this idea of thought+action. Even robotics uses ReAct: an LLM can plan high-level steps (“I need to pick up the object” → calls a robot arm API to do it, etc.). ReAct is powerful whenever you need an AI to do something in addition to thinking.
Limitations: While ReAct is transformative, it requires careful prompt design to keep the reasoning and acting outputs separate and structured. There’s also a risk that the model’s “thoughts” could go off track or the model could hallucinate an action that doesn’t exist. To mitigate this, developers restrict the available actions and sometimes insert validation steps. Despite these challenges, ReAct is a major step toward more agentive AI – systems that can autonomously reason about tasks and execute them in the real world.
Reflexion: Learning from Mistakes
Humans learn by trial and error: when we get something wrong, we analyze the mistake and try again. The Reflexion technique brings a similar ability to LLMs – it allows a model to reflect on its own output, receive feedback (even if just from itself), and then attempt the task again with the benefit of hindsight. In short, Reflexion turns a single-pass LLM into an iterative problem-solver that can improve itself without additional training.
What It Is: Reflexion is a framework where the model engages in a loop of attempt → feedback → reflection → new attempt. Importantly, the feedback can be given in words and stored in the model’s memory for subsequent attempts. This is not updating the model’s weights (no gradient descent or fine-tuning in between tries); instead, the model writes down a critique or summary of what went wrong or what could be improved, and that text is provided as context for the next round. It’s akin to the model talking to itself: “I tried to solve it and got it wrong. Here’s why I think it was wrong. Now, armed with that insight, let me try again correctly.”
How It Works: In practice, implementing Reflexion might involve the following steps for a given task or question:
- 1. Initial attempt: Prompt the model to answer the question or solve the task as normal. Get an output answer/solution.
- 2. Feedback signal: Determine if the answer was correct or not. This could come from an external source (e.g., a unit test for a coding problem, or a factual checker for a trivia question) or even from the model itself if it’s able to verify partially. For example, if the task was to produce code that passes certain tests, the tests results are the feedback (pass/fail).
- 3. Reflection: If the answer was wrong or suboptimal, prompt the model to reflect on it. This could be done by saying: “You made a mistake. Here was your answer: ... It failed because ... . Why did your solution not work? What should you do differently?” The model then produces a reflection, like a brief analysis or lesson. For instance: “My code didn’t account for the case X, causing an error. I should fix that.” This reflection is stored in an episodic memory (just a text buffer).
- 4. Retry with memory: Now the model is prompted again to solve the task, but this time the prompt includes the content of the reflection (and possibly the previous attempt) as additional context. Essentially, the model “remembers” what it learned from the last try. It then produces a new solution that ideally avoids the previous mistake.
- 5. Iterate: This process can repeat for multiple trials until the model gets it right or reaches a maximum number of iterations. Each time, new feedback is appended and more reflections accumulate, guiding the model toward a correct solution.
The core idea is to create a feedback loop where the LLM is in the loop, rather than a human. The model’s own reflective notes serve as training wheels for its next attempt. Researchers Noah Shinn et al. (2023) described it as using “linguistic feedback” to reinforce the agent instead of updating the model weights.
Example Scenario: A concrete example comes from coding. Suppose the task is: “Write a function that checks if a number is prime.” An LLM might generate a solution. We then run some tests on that code (action outside the model) and discover it fails for a certain input (say, it mistakenly identifies 1 as prime). We feed that back: “Test failed for input 1. The output was incorrect.” The model reflects: “I forgot that 1 is not prime. I should handle that case explicitly.” Now, on the next attempt, the model includes a check if n <= 1: return False and the code passes. This iterative improvement mimics how a programmer debugs code, and indeed Reflexion was shown to massively improve coding task success rates. In one study, an LLM using Reflexion reached 91% accuracy on the HumanEval coding benchmark, surpassing even GPT-4 (which scored 80%). The iterative self-correction gave a smaller model the ability to outperform a larger one by sheer persistence and learning from its mistakes.
Use Cases: Reflexion is useful in scenarios where initial attempts often fail, but there are ways to detect failure and try again. Coding is a prime example (you can run the code and get errors/tests as feedback). Another example is multi-step reasoning problems: if an answer seems obviously wrong, the model can be nudged to reconsider. Even for question-answering, one could have the model double-check its answer by posing a follow-up (like “Are you sure? Could there be another interpretation?”) – this is a mild form of self-reflection. Reflexion-style approaches can also reduce hallucinations in generation. If a model answers a factual question and a fact-checker tool says “that is incorrect,” the model can reflect and correct itself instead of requiring a human to intervene. It’s an “LLM-in-the-loop” form of self-supervision.
Who’s Using It: Reflexion was introduced in a research context, but its influence is spreading. The concept of an LLM agent that “thinks about what it did wrong” is being incorporated in experimental AI agent frameworks. For instance, some open-source projects that extend AutoGPT or BabyAGI have added “memory” components where the agent evaluates past actions and adjusts strategy. Anthropic’s Claude model has a known tendency to offer to double-check or critique its answer if asked, which is related in spirit. We also see Reflexion ideas in reinforcement learning with language feedback – e.g., using an LLM to critique another LLM’s output and feed that in as guidance (a technique OpenAI and others have explored for safer, more accurate answers).
At a high level, Reflexion brings models closer to a human-like approach of iterative refinement. Rather than one-and-done responses, the model treats solving a task as a process, potentially with multiple attempts. This makes AI more reliable on hard problems. As one blog author put it, it’s like having a “self-criticism” or “self-check” stage that can catch mistakes and prevent hallucinations before finalizing an answer.
Analogy: A good analogy used to describe Reflexion is writing and revising an essay. The first draft might not be perfect. Upon rereading (feedback), you notice some arguments don’t make sense or a paragraph is out of place. You then reflect on how to improve it (“Maybe I need to clarify this point, or fix that factual error”). With those notes in mind, you write a second draft that’s better. Reflexion gives LLMs a similar second chance through self-feedback. This technique, combined with others, contributes to making AI reasoning more robust and trustworthy over multiple interactions.
Chain-of-Action-Thought (CoAT)
Chain-of-Thought gave models a way to break down problems, but as we saw, it had limitations – the model might blindly continue a flawed reasoning chain. Chain-of-Action-Thought (CoAT) is a 2025 innovation that generalizes chain-of-thought by introducing special “meta-actions” into the reasoning process. In CoAT, at each reasoning step the model can decide not only to continue, but also to do things like reflect on the current progress or try a different approach. It’s like giving the model an internal toolkit for better reasoning management.
How It Works: Researchers implementing CoAT provided the model with a set of special tokens that represent meta-cognitive actions. The main ones are:
- Continue (
<|continue|>) – meaning “Proceed with the next step as normal.” (This is essentially the default action, akin to a regular chain-of-thought step.) - Reflect (
<|reflect|>) – meaning “Pause to double-check or verify the previous steps for errors or misconceptions.” This prompts the model to effectively inspect its own reasoning so far. - Explore alternative (
<|explore|>) – meaning “Something might be wrong; go back and try a different approach.” This signals the model to branch off from the current line of thinking and attempt a new solution strategy from that point.
When using CoAT, a model’s reasoning trace might look like a series of thought steps each prefixed by one of these meta-action tokens. For example, solving a math problem, the model could do:
<|continue|>“Let me compute the discriminant of this quadratic.” → (computes and finds a value)<|reflect|>“Wait, that value seems off. Did I square the numbers correctly? Let’s check the arithmetic.” → (recalculates) → “Ah, I made a mistake earlier.”<|explore|>“I’ll try a different approach: maybe solve the equation by factoring instead.” → (new attempt begins)<|continue|>“This approach is working, continuing with it step by step.” → … → Final answer.
In a standard CoT, the model never had the chance to explicitly reflect or restart in the middle of the reasoning; it would either carry on or stop. CoAT opens up those possibilities mid-stream, under the model’s own control.
Training for CoAT: Of course, models don’t innately know how to use <|reflect|> or <|explore|> tokens. In the original research (which produced a model named Satori), the authors used a two-stage process: first, a “format tuning” on some data with these special tokens to familiarize the model with the concept, and second, a reinforcement learning stage where the model is rewarded for using these meta-actions effectively to improve problem-solving. For example, the model might be trained on examples where a reflection token precedes catching an arithmetic error, or an explore token precedes trying a different solution path when the first path was leading nowhere. Over time, the model learns when to insert a <|reflect|> (e.g. if it’s unsure or a check is needed) and when to use <|explore|> (e.g. after detecting a logical dead-end).
Why It’s Exciting: Chain-of-Action-Thought essentially gives the model a form of internal self-regulation. Instead of relying on an external mechanism (like a user or a separate checker) to say “stop, you might want to reconsider,” the model can do this autonomously. This yields big gains on challenging tasks. The CoAT-enabled model Satori (7 billion parameters) achieved state-of-the-art performance on multiple math reasoning benchmarks. For instance, it significantly outperformed previous models on problems from the GSM8K math dataset and others, despite being relatively compact. The ability to reflect and course-correct during reasoning leads to more accurate final answers because the model isn’t just plowing ahead with a flawed assumption – it can catch itself. In one example given, the model initially made an error in solving a problem, but then inserted a “<|reflect|> Wait, let me verify…” step, noticed the mistake, and fixed it before arriving at the final answer. This kind of mid-problem introspection is exactly what human problem-solvers do (we often pause and double-check a result that looks fishy, or decide to scrap an approach if it’s not working).
Use Cases: CoAT is particularly useful for long, multi-step problems such as complex math (where checking intermediate results is crucial), logical deduction puzzles, or any domain where a solution might require revisiting earlier steps. It’s essentially a built-in mechanism for error correction and strategy shift. One can imagine future coding assistants using CoAT to decide when to unit-test their own code mid-generation (<|reflect|> could trigger a quick self-test routine) or a medical diagnosis model using <|explore|> to say “let’s consider a different diagnosis path given the symptoms aren’t adding up with the current assumption.”
Who’s Using It: Chain-of-Action-Thought is brand-new from the research labs. The Satori model that pioneered CoAT is being open-sourced, which means the broader community will be able to experiment with it. It’s likely that academic and industry researchers (perhaps at places like Google DeepMind or OpenAI) are closely watching these developments. CoAT aligns with the general trend of making LLM reasoning more reliable – which is of high interest to companies wanting dependable AI. We might see variants of this idea in next-gen systems; for example, Anthropic’s Claude has a notion of “Introspection” in its safety training, and OpenAI’s approach to GPT-4 involved some internal monitoring of reasoning. CoAT formalizes it in the prompt/training level. It wouldn’t be surprising if future GPT or PaLM models incorporate something like CoAT to reduce mistakes on the fly.
In summary, Chain-of-Action-Thought extends the model’s autonomy in reasoning. Instead of only one mode (continue), it has multiple modes (continue, reflect, restart) for managing its solution path. Early results are very promising, showing that even relatively small models with CoAT can out-think larger ones that lack these meta-reasoning abilities. As LLMs tackle more complex tasks, these internal “steering mechanisms” will be key to better performance.
Flow-of-Options (FoO)
A very recent technique pushing the frontier of LLM reasoning is Flow-of-Options (FoO), introduced in early 2025. If CoAT gave models internal decision modes, Flow-of-Options gives models a structured way to consider many solution options and combinations – effectively tackling the model’s tendency to go with the most obvious answer. FoO is designed to overcome intrinsic biases of LLMs by forcing a more diversified exploration of possible solutions.
What It Is: Flow-of-Options is like building a directed acyclic graph (DAG) of reasoning steps. Each node in this graph represents an option for a particular step of a task, and edges connect options in a sequence. By organizing reasoning as a DAG, FoO allows an LLM to try different methods at each stage and later merge paths or choose the best path through the graph. It’s a bit similar to Tree-of-Thoughts, but with a more structured and domain-guided approach, often used for complex multi-step tasks like machine learning workflows or chemistry problems.
How It Works: The Flow-of-Options framework can be summarized in a few key components:
- Option Generation: For each step of a task, instead of doing one thing, the model generates k different possible options for that step. For example, if the task is to build a data science model, Step 1 might be “choose data preprocessing method,” and the model proposes multiple options (normalize data, remove outliers, do nothing, etc.). This ensures a broad exploration, rather than the model always picking its single most likely guess (which could be biased from its training). These options are nodes in the graph at that depth.
- Network Structure (DAG): The options are arranged in a directed acyclic graph reflecting the task sequence. There’s a start node (dummy root) and then layer 1 has the options for step 1, layer 2 has options for step 2, etc., with edges connecting each option in step 1 to each option in step 2 (and so on) to form possible complete solutions (a path from start to end through the graph).
- Walking the Graph (Traversal): The system then explores combinations of options by walking through this graph. It’s not going to try all combinations blindly if there are many; typically a beam search or heuristic is used to keep the exploration tractable. For instance, it might always keep the top b promising partial paths at each step (selecting the best few options at step 1 to combine with best few at step 2, etc.).
- Consistency Checking: After forming a full sequence (picking one option per step to get a candidate solution), the system checks if the steps are consistent with each other. This is important because when combining options generated independently, they might conflict. (Imagine one step’s option assumes using algorithm A, but another step’s option assumes a setting only valid for algorithm B.) An LLM-based consistency checker can verify that the chosen options don’t contradict – if they do, that path is invalidated.
- Case-Based Reasoning (Memory): FoO also incorporates a memory of past successful option flows. If a similar task was solved before with a certain sequence of options, the system can retrieve that and use it as a guide (adapting it to the new task). This prevents starting from scratch every time and is akin to using previous cases/experiences to inform current reasoning.
- Option Selection (Result): Finally, after evaluating possible flows, the best performing or most appropriate sequence of options is selected as the solution plan.
In effect, Flow-of-Options forces the model to consider alternatives at each step and not to prematurely converge on one line of thinking. It’s very useful for domains where there are multiple ways to solve a problem and the “obvious” way isn’t always the best.
Use Case Scenario: The paper introducing FoO demonstrated it on complex tasks like designing drug molecules and data science modeling. Take a data science task: “Build a model to predict patient recovery time from medical records.” An LLM might have biases (perhaps it’s seen more examples of using linear regression, so it defaults to that). FoO would make it propose, say, five different modeling approaches (linear reg, random forest, neural network, etc.). It would also propose options for data cleaning (maybe normalization vs. no normalization) and for feature selection methods. This creates a graph of possible pipelines. The system might then evaluate a few combinations: perhaps it finds that Option 1: normalize data + random forest + select top 10 features yields a better result than the default Option 2: no normalization + linear regression + select all features. Without FoO, the model might have picked Option 2 because linear regression is a common pattern it knows, missing the better solution. With FoO, it gains diversity and can outperform state-of-the-art by exploring non-trivial combinations.
In fact, the results reported are impressive: FoO achieved 38% to 69% improvements on data science tasks, and ~37% to 48% improvements on therapeutic chemistry tasks, over previous best approaches. These are big jumps in performance, attributed to the model not getting trapped by its own training biases and instead systematically searching through alternatives. Essentially, it “nurtures broader exploration of potential solutions” and yields “substantial performance gains… in multiple domains”.
Who’s Behind It: Flow-of-Options comes from a collaboration that includes AI researchers and likely industry (the GitHub repo is under an organization named FlagshipPioneering, which suggests involvement from an R&D firm or startup). It’s cutting-edge as of 2025, with an arXiv paper published in February 2025. Companies interested in complex decision-making (like biotech firms for drug design, or any field where you want an AI “research assistant” to try multiple approaches) will find this technique useful. It might not yet be in mainstream use, but it’s conceptually influencing how we think about de-biasing LLM reasoning. IBM’s description of ToT even hinted at “self-consistency mechanism... by prompting the model multiple times”, which is related. FoO takes that to another level by systematically structuring the multiple attempts.
Where It Shines: FoO is great for tasks that have sequential decision points with several options each, especially where the best combination isn’t obvious. Think of planning tasks (like multi-step processes), complex Q&A that might require choosing different tools or methods per sub-question, or even story generation (where at each plot point you could explore different narrative options – though FoO’s current form is more for analytical tasks). By enforcing diversity at each step, FoO ensures the model doesn’t put all its eggs in one basket. It’s a remedy for the training bias where an LLM might always say, for example, “use method X” because it saw that often in training data. With FoO, it has to also say “or method Y, or Z” and then logically decide which yields the best outcome.
Challenges: Like Tree-of-Thought, FoO is computationally heavy – generating multiple options and evaluating combinations is expensive. The authors mitigated cost by using case-based reasoning and noting that once a good flow is found, it can be reused cheaply. They also reported that their system could keep the cost to under $1 per task with optimizations, which is promising for practical use. Another challenge is that FoO currently requires a fairly structured task definition (knowing the “steps” in advance). It’s easiest to apply when you can clearly break a task into steps like a workflow.
Despite these, Flow-of-Options represents a significant advance in making LLM reasoning more systematic and less greedy. It’s like giving the model a project plan with branching options at each milestone, rather than a straight line. As AI tackles more complex, multi-faceted problems (in science, engineering, etc.), techniques like FoO will be valuable to ensure we’re not missing creative or superior solutions due to AI’s ingrained habits.
Other Emerging Reasoning Techniques
Beyond the major techniques above, there are a few other notable strategies and trends (circa 2025) aimed at improving LLM reasoning:
- Self-Ask Prompting: This is a method where the model is encouraged to ask itself (or an external tool) follow-up questions before answering. Instead of directly outputting an answer, the model may produce a sub-question like “What information do I need to solve this?” and then answer that sub-question, possibly using a tool to find the answer. It then uses the result to address the original query. This technique, introduced by researchers in 2022, effectively breaks a problem into a Q&A with itself. For example, for a question “How old was the President when X happened?”, a self-ask approach might have the model first ask “Who was the President at that time?” → find answer, then ask “What was that President’s age at that year?” → compute answer, and finally respond with the age. Self-Ask is somewhat similar to ReAct, but it emphasizes the model formulating explicit questions as intermediate steps. It’s used in some QA systems and was a precursor to the more general ReAct framework.
- Self-Consistency Decoding: We touched on this under CoT – it’s worth highlighting as a general technique. Instead of relying on one chain of thought, the model generates many and then picks the answer that appears most frequently among them. This leverages the idea that while any single reasoning path might go astray, the correct answer is likely to crop up in several independently sampled reasoning paths if the model does know what it’s doing. By choosing the most consistent answer, accuracy improves. Think of it as crowd-sourcing from one model by asking it the same question in multiple ways and taking the consensus. This has proven very effective in arithmetic and commonsense tasks, and it can be applied on top of CoT, ToT, or others.
- Tool-augmented CoT: While ReAct covers reasoning+acting, a simpler variant that’s popular is just augmenting chain-of-thought with specific tools for certain steps. For instance, an LLM might do normal CoT reasoning but whenever it needs a factual lookup, it pauses and calls a search engine (via a pre-set mechanism), then resumes reasoning with that info. OpenAI’s function calling and tools can be seen as an extension of this idea. It isn’t a separate reasoning paradigm, but a practical pattern: the model’s chain-of-thought is supported by external knowledge or calculations on demand. Google’s PaLM 2 and OpenAI’s GPT-4 both have demonstrated abilities to use tools like calculators, which is essentially injecting an action into the thought stream.
- Socratic Models & Debate: Another interesting approach (though more in research) is to have multiple models debate or question each other’s reasoning. For example, one model generates a solution and another is prompted to critique it or ask questions about it (like a Socratic teacher). The first model then refines its answer. This externalized reflection can improve reasoning and is related to Reflexion, except the “critic” is a separate model. OpenAI’s earlier idea of “AI debate” also falls here – where two models argue and a judge (could be a model or human) decides who made the better case. While not widely deployed, these multi-agent or multi-step interactions are being explored to reduce reasoning errors and biases.
- Plan-and-Solve (Modular Reasoning): Some tasks benefit from explicitly splitting the planning from the execution. A pattern here is to prompt the model to first output a plan (maybe a numbered list of steps or a high-level summary of what it will do), and then in a second stage, actually produce the detailed answer following that plan. This two-stage approach can be seen in certain prompt designs for complex tasks. It’s not as formalized as CoT or ReAct, but it’s a heuristic that often leads to better organized answers. For instance, Anthropic’s Claude often internally generates a “scratchpad” of thoughts even if the user doesn’t see it – effectively planning before answering. By separating the “thinking” phase and the “answering” phase, the model can catch inconsistencies in the plan before it commits to a final answer.
- Interactive Prompting and Correction: In user-facing applications, one emerging practice is designing the system prompt to encourage the model to double-check answers. A system message might say, “If you’re not sure, reason it out step by step, and verify each step.” This doesn’t always work, but it nudges models like GPT-4 to internally do more reasoning (sometimes invisible to the user) especially for tricky questions. OpenAI has also experimented with a technique where after the model gives an answer, they run another pass where the model is asked, “Is there any flaw or mistake in the above solution? If so, correct it.” This is like an automatic review phase. It connects to Reflexion – but done in a single chat exchange by the system rather than multiple user turns.
All these techniques share a common theme: making LLMs more deliberative and less impulsive. Instead of treating a query as something to answer in one go, the model treats it as a problem to solve through reasoning, asking, checking, and other intermediate operations. The field is moving fast – what’s cutting-edge in 2025 may well be surpassed by even more sophisticated methods, but these represent the state of the art in teaching AI to “think.” Each can be combined with others: for example, you could have a Tree-of-Thought agent that uses Reflexion at each node, or a Chain-of-Thought with self-consistency and tool use. Companies like OpenAI, Google, Anthropic, Meta, and many academic labs are actively researching in this space, often sharing ideas in blogs and papers that build on one another.
Conclusion
The progress in reasoning techniques for LLMs over the past couple of years has been astounding. We’ve gone from straight one-shot answers to prompting models with “Let’s think step by step” and seeing emergent reasoning, and now to elaborate frameworks where models can branch out thoughts, call tools, reflect on errors, and systematically explore options. These advancements make AI not only more powerful, but also more transparent – we can often follow why an AI arrived at an answer by looking at its chain of thought or tree of exploration.
For tech enthusiasts, it’s exciting to know that when you ask a complex question to a modern AI, under the hood it might be doing all sorts of clever reasoning tricks: reasoning through a chain of logic, considering multiple hypotheses, checking its work, maybe even querying a database – all orchestrated by prompts and internal policies designed by researchers. For researchers, each of these techniques is a piece of the puzzle toward reliable and general problem-solving AI. They address different challenges (CoT combats shallow reasoning, ToT handles planning, ReAct enables tool use, Reflexion reduces mistakes, CoAT gives self-control, FoO fights bias), and together they significantly expand what language models can do.
In practical applications, these techniques mean better performance on everything from math tutors and coding assistants to search engines and autonomous agents. Companies are already incorporating them: OpenAI’s and Anthropic’s systems use chain-of-thought and tool use, Google’s PaLM uses prompting strategies inspired by these methods, and new open-source models are being fine-tuned to produce reasoning traces. As users, we might notice that AI explanations are getting more logical and step-by-step – that’s CoT in action. We might see AI agents on the web that can cite sources, use calculators, or browse for you – that’s ReAct. And when an AI says, “Hmm, let me double-check that,” and corrects itself, that’s Reflexion at work.
What’s next? Perhaps even more meta-reasoning – AI that can reason about which reasoning strategy to use (a sort of self-optimization). Or more hybrid human-AI collaboration where the AI’s chain-of-thought is exposed to users so we can guide it. The landscape is evolving rapidly, but the techniques we discussed here are likely to remain fundamental building blocks.
In summary, large language models are no longer just predictive text machines; they are becoming reasoners and problem solvers. Techniques like CoT, ToT, ReAct, Reflexion, CoAT, and FoO are teaching machines to approach problems in human-like (and sometimes superhuman) ways – breaking problems down, exploring alternatives, using tools, learning from mistakes, and systematically eliminating error. It’s a fascinating time at the intersection of AI and reasoning, and these methods are turning yesterday’s clever trick into tomorrow’s standard practice. With each innovation, we get a step closer to AI that can truly think things through.