Introduction to generative adversarial networks
Introduction to GANs and Their Impact
Generative Adversarial Networks, or GANs, are a class of AI models that can create new data resembling real data. They were introduced by Ian Goodfellow and colleagues in 2014 and have since revolutionized generative modeling in AI. Instead of just recognizing patterns, GANs generate entirely new examples: for instance, producing a new image that looks like a real photograph. In less than a decade, GANs have made a huge impact – enabling AI to paint artworks, invent realistic human faces, and even assist in scientific simulations. This transformative power has far-reaching implications across art, entertainment, science, and more. At the same time, GANs have raised concerns (like convincing deepfakes) alongside their positive applications. Overall, GANs represent an exciting leap forward in AI’s ability to mimic and create reality, opening up both creative opportunities and important discussions about ethical use.
How GANs Work: Generator vs. Discriminator
At the heart of a GAN are two competing neural networks: the generator and the discriminator. You can imagine the generator as a forger or artist, and the discriminator as a detective or art critic. The generator’s job is to create fake data (for example, synthesizing an image that looks like a real photo), while the discriminator’s job is to examine data and judge whether it is real or fake.
Here’s how they train together: the generator starts by taking a random input (often called noise or a latent vector) and uses it to produce a sample – say, an image that it hopes could pass for a real image. The discriminator then sees both real examples (genuine data from the training set) and the generator’s fake examples, and it tries to tell the difference, labeling each as “real” or “fake.” Initially, the generator’s outputs are poor quality, and the discriminator can spot them easily. However, the feedback from the discriminator (essentially, what features made the fakes look fake) is used to update the generator. The generator adjusts its internal parameters to try to make more realistic outputs that fool the discriminator next time. Conversely, the discriminator also updates its parameters to better catch the generator’s improved fakes.
This process sets up a competitive game: the generator is constantly learning to fool the discriminator, and the discriminator is learning to become a better critic. Over many rounds of training, the generator hopefully becomes so good at producing realistic data that the discriminator can no longer reliably tell fake from real – in theory, it will be correct only 50% of the time, as if it’s just guessing. When this balance is reached, we say the GAN has converged: the generator is generating data that is indistinguishable from real data (at least to the discriminator’s eyes). In practice, training GANs is tricky and this ideal equilibrium may be hard to achieve, but this adversarial training process is the key idea. The result is an AI system that learns by competition, yielding a generator capable of amazing creativity – from dreaming up realistic images to imagining new music – all through this generator-vs-discriminator dance.
Important GAN Variants: cGANs, Pix2Pix, CycleGAN, StyleGAN
a. Conditional GAN (cGAN)
The original GAN is unconditional, meaning it just generates data freely. A Conditional GAN (cGAN) is an extension where both the generator and discriminator receive some additional information (condition). This condition could be a class label, a text description, or even another image. By providing a condition, we can control what the generator creates. For example, with labels as conditions, a cGAN can be told to “generate a photo of a cat” versus “generate a photo of a dog.” Both networks learn not only to make or detect fakes, but to do so in context of the given condition. This makes cGANs very powerful for directed tasks – we’re no longer just generating random outputs, but steering the generation toward a desired category or style.
b. Pix2Pix
Pix2Pix is a popular example of a conditional GAN applied to image-to-image translation. It was introduced in 2017 as a method to learn a mapping from one type of image to another, given paired examples. For instance, Pix2Pix can learn to convert outline sketches into colored photographs, or turn satellite images into maps (and vice versa), as long as it has training pairs of inputs and desired outputs. The generator in Pix2Pix takes an image as input (instead of random noise) and learns to transform it, while the discriminator checks if the output image looks like a believable target image. This approach is supervised (it requires matching pairs for training), but it achieves impressive results in tasks like colorizing black-and-white photos, turning line drawings into realistic images, or enhancing rough scans.
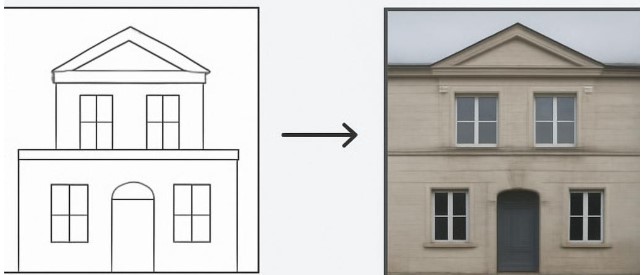
Figure: Pix2Pix can translate one type of image to another.(right).
c. CycleGAN
What if you want to do image-to-image translation without paired data? That’s where CycleGAN comes in. CycleGAN (introduced in 2017) learns to translate between two visual domains using unpaired datasets – for example, given a bunch of horse photos and a bunch of zebra photos, it learns to convert a horse image into a zebra image, and vice versa, without ever seeing direct horse→zebra pairs. It does this by employing two generators (one for A→B and one for B→A) and two discriminators. A clever cycle-consistency constraint is used: if you convert an image from domain A to domain B and then back to A, you should get back the original image. This cycle-consistency loss forces the mappings to preserve the content of the image while changing the style. CycleGAN opened up possibilities for unpaired style transfer: you can transform photos to paintings, summer scenes to winter, day to night, etc., using only sets of example images from each style. The results are often astonishing – imagine changing the style of a photograph to look like a Van Gogh painting, or turning a picture of your pet cat into the style of a lion – all learned from unpaired data. CycleGAN showed that GANs can learn transforms between domains even when aligned pairs aren’t available, greatly widening practical applications.
d. StyleGAN
As GANs matured, researchers began focusing on generating images at higher quality and resolution. StyleGAN, developed by NVIDIA researchers (first version in 2018, with improved versions StyleGAN2 and StyleGAN3 later), is a GAN architecture famous for producing extremely realistic high-resolution images, especially of human faces. StyleGAN introduced a new generator design that allows control over different levels of detail (styles) in the image. In StyleGAN, the random input vector is first mapped into an intermediate latent space, and this is used to modulate (control) the synthesis at various layers of the generator. This design lets the model separate high-level attributes (like pose, general face shape) from finer details (like skin texture, freckles) – so one can mix and match “styles” from different sources. For example, you could generate a face that takes the overall layout from one random source (say, face shape and hair) but the fine details (like colors or textures) from another. StyleGAN and its successors can generate faces at 1024×1024 resolution that are nearly photorealistic. Beyond faces, they have been applied to bedrooms, cars, animals, and more. The level of realism is so high that many StyleGAN-generated faces are virtually indistinguishable from photos of real people. This has powered fun web demos (like “This Person Does Not Exist” which shows a new fake face each refresh) and has also raised awareness of how advanced generative tech has become. StyleGAN’s ability to control visual attributes and produce diverse, lifelike images makes it a milestone in GAN research.

Figure: None of the people shown here are real. These faces were generated by StyleGAN, demonstrating how a GAN can learn to create lifelike human images from scratch. The model has learned facial structures, features, and details so well that the outputs can closely mimic real photographs. This showcases the power of modern GANs for producing high-fidelity, believable images.
Source: whichfaceisreal.com
These are just a few highlights among many GAN variants (others include DCGAN for using deep convolutional networks, WGAN for improving training stability, InfoGAN for learning interpretable features, etc.). Each variant tweaks the basic GAN idea to target a different aspect – whether it’s adding conditions, improving quality, or tackling new tasks. Together, they show how flexible the GAN framework is, spawning innovations in creative image manipulation, domain translation, and high-quality content generation.
Evaluation Methods for GANs (Especially FID)
Training a GAN is one challenge, but how do we evaluate the results? Unlike a classifier which has accuracy, a generative model’s output is subjective – what makes a generated image “good”? This is an open question in AI, but over time, some evaluation methods have been developed:
One straightforward check is human evaluation: showing a human evaluator a mix of real and generated images to see if they can tell them apart, or asking humans to rate the quality. While this is the gold standard (since ultimately we care if outputs look real to people), it’s expensive and time-consuming to do at scale.
To automate evaluation, researchers introduced metrics like the Inception Score (IS) and the Fréchet Inception Distance (FID). These metrics use a pretrained image classification network (typically the Inception-v3 model, known for its image recognition capabilities) to analyze the GAN outputs. The Inception Score looks at how confident the classifier is in its predictions for generated images (on the idea that a realistic image should strongly appear to be some recognizable object) and also checks that there is variety in the outputs across classes. A higher Inception Score can indicate the images are both meaningful and diverse. However, IS doesn’t directly compare to real data and can be gamed or not reflect human perception in some cases.
The Fréchet Inception Distance (FID) has become a more commonly used metric. FID compares the statistics of generated images to those of real images. In practice, we take a large set of real images and a set of generated images, pass them through the Inception network to get high-level feature representations, and then compute the Fréchet distance (a type of distance between two probability distributions) between the feature vectors of real vs. fake images. Without getting into the formula, what it produces is a score — lower FID is better, meaning the generated data’s feature distribution is very close to the real data’s distribution. For example, if your GAN is generating faces, a low FID would mean that in the Inception network’s feature space, the fake faces sit in about the same cloud as the real faces, implying similar statistics in terms of things like facial features, lighting, etc. FID has been useful because it penalizes both lack of quality and lack of diversity: if the GAN outputs are blurrily average or if they collapse to very few varieties, the distance will be larger.
An intuitive way to think of these metrics: they try to answer, “Do the GAN’s outputs look like they came from the same distribution as the real data?” A perfect GAN would produce outputs indistinguishable from real data, so the distributions would match and FID would be extremely low. In practice, even the best models have some gap. For instance, StyleGAN on faces achieves a very low FID compared to earlier models, reflecting its high realism.
It’s important to note that no single metric is perfect. FID might not capture specific flaws (like weird artifacts that humans notice), and a good metric score doesn’t always mean the images look great to us. Therefore, researchers often use a combination of metrics and visual examination. As GANs continue to improve, developing better evaluation methods is an active area of research. For now, metrics like FID provide a handy, if imperfect, way to quantitatively track GAN performance and compare models.
Bias in GANs: How to Detect and Reduce It
Like all machine learning models, GANs can inherit biases from their training data. This means if the data used to train a GAN has an underrepresentation or skew toward certain attributes, the GAN’s outputs will reflect that. For example, imagine a GAN trained on a faces dataset that is 90% men and 10% women – the generator may end up producing mostly masculine faces and very few feminine faces, effectively perpetuating the imbalance. Similarly, if the training images of people are mostly of a certain ethnic background, the GAN might rarely generate faces of other backgrounds. This raises concerns about fairness and diversity in generative models.
Detecting bias in GAN outputs involves analyzing the generated samples in aggregate. One could use classification tools or human evaluation to label attributes in a large batch of generated images – for instance, determining the demographic or other characteristics of people the GAN creates – and then checking if those proportions are significantly skewed compared to a fair or desired distribution. Another approach is to see if the GAN fails to produce certain categories altogether (e.g. never generates a certain type of object or style that was rare in the training set). If such gaps or imbalances are observed, it’s a sign that the GAN has picked up on and is amplifying biases present in the training data. Researchers have even pointed out that some GANs learning to generate faces might accentuate societal biases (for example, defaulting to lighter skin tones if the training data wasn’t balanced).
Reducing bias in GANs often starts with the data: ensuring the training dataset is as diverse, representative, and balanced as possible. Since the GAN can only learn from what it’s given, curating the data to include a wide range of groups or styles helps the generator not fall into a one-dimensional output space. Besides data curation, there are also technical methods: one can incorporate regularization or penalty terms during training that encourage the GAN to produce diverse outputs. For instance, some approaches add an auxiliary network or classifier to the GAN setup that checks for a particular attribute in the output (like gender or ethnicity in faces) and tries to enforce a balance. If the GAN leans too heavily one way, the training loss can be adjusted to push it toward generating underrepresented variants. Another strategy is to use conditional GANs with labels for sensitive attributes and explicitly instruct the generator to produce outputs across all those label values – essentially telling it to spend equal effort on different categories. There’s also research into fairness-aware GAN objectives (such as “Debiasing GANs”) that aim to minimize the correlation between generated output and certain unwanted bias variables.
It’s worth noting that completely eliminating bias is difficult, especially if real-world data itself is biased. However, awareness of this issue is growing. AI practitioners now test GANs not just for visual quality, but also for ethical quality – checking if the model is fair and doesn’t reinforce problematic biases. For example, a GAN used for creating avatar faces should generate a spectrum of skin tones, ages, genders, etc., appropriate to the intended use, rather than just one archetype. Similarly, if GANs are used in content generation for industries like fashion or advertising, diversity in output is crucial. Tools and techniques for auditing AI-generated content are emerging to flag bias, and mitigation techniques (like rebalancing datasets or tweaking models) are applied to address it.
In summary, GANs are powerful, but with great power comes the responsibility to ensure they respect diversity and fairness. By carefully preparing training data and adjusting training methods, developers can reduce bias in GAN outputs. Ongoing research in this area continues to improve how we measure bias in generative models and how we can create AI that is not only creative and realistic, but also fair and inclusive.
Real-World Applications of GANs
GANs might sound abstract, but they’re behind many exciting applications across different fields. Here are some notable real-world uses of GAN technology:
Data Augmentation and Synthetic Data: In machine learning, having more training data can improve models – but collecting real data can be hard or sensitive (think medical images or rare-event data). GANs step in by generating additional synthetic data that is close to the real thing. For example, in medical imaging, a GAN can generate realistic-looking MRI scans or X-rays to augment a small dataset, helping train diagnostic models. In scenarios where privacy is a concern (like patient data or personal faces), GANs can create new examples that preserve statistical patterns without using any one person’s data. This privacy-preserving data generation means researchers and companies can work with “data” that has the realism of real datasets but isn’t tied to actual individuals. It’s a promising approach to sharing insights from data without exposing the real data itself.
Art and Creative Design: GANs have unlocked new frontiers in digital art. Artists and designers use GANs to create novel images, paintings, and designs that would be hard to imagine manually. There are GANs that generate paintings in the style of famous artists, allowing for new artworks that blend styles or mimic masters. Photographers use GAN-based style transfer to apply artistic filters to photos (turning a city skyline photo into an image that looks like a Van Gogh painting, for instance). In graphic design, GANs can generate textures, patterns, or even product designs. The creative possibilities are enormous – you can have an AI imagine architecture, invent new fashion (by generating images of apparel or shoes), or even assist in music and literature (GAN-like models that generate melodies or written text). The key is that GANs can learn aesthetics from data and then produce original works that follow those aesthetics. This has led to a new genre of art exhibitions featuring AI-generated pieces and tools that let anyone create art with the help of GANs.
Image-to-Image Translation and Enhancement: Many practical applications involve translating one form of imagery to another. We already discussed Pix2Pix and CycleGAN which are used in tasks like photo enhancement, editing, and translation. Some examples in use:
- Photo Restoration and Enhancement: GANs can colorize old black-and-white photos, remove noise or scratches, and even increase resolution (a task known as super-resolution). For instance, given a low-resolution image, a GAN-based super-resolution model (like ESRGAN) can produce a higher-resolution version with added details that look plausible. This is used in sharpening security camera footage or upscaling old family photos.
- Face Editing: There are GAN tools that let you modify facial features in images – for example, change someone’s expression, age, or hairstyle. Apps have appeared (some using variations of CycleGAN or other GAN architectures) that can take a selfie and age you by decades, swap genders, or apply other transformations while keeping the image photorealistic. These fun transformations are powered by training GANs on large datasets of faces with those attributes.
- Style Transfer and Domain Conversion: As mentioned, CycleGAN can do things like turn horses into zebras, summer scenes to winter, day to night. This has practical use in cinematography and game development: imagine converting video footage shot in daytime to a believable night version, or making a synthetic scene look like real-life video by translating game graphics to photorealism. In autonomous driving research, CycleGANs have been used to translate simulated road images to look realistic, so that models trained in simulation can better transfer to real world. GANs have even been used to generate virtual data for training robots, such as creating new views or scenarios that help a robot learn, without having to physically experience every scenario.
- Anomaly Detection and Privacy: Interestingly, GANs can also assist in security and privacy from the other side. For example, a GAN can generate anonymized versions of faces (retaining expression but altering identity) for video conferencing or surveillance footage, protecting individual identity while allowing analysis. Conversely, in cybersecurity, GANs are being used to generate fake but realistic network traffic or user behavior to train intrusion detection systems (though this is more generative modeling in spirit, not a typical image GAN scenario, it’s a conceptual extension). GANs have also been experimented with for anomaly detection: a GAN is trained on normal data, and then if something very unlike the training distribution appears, the GAN (or discriminator network) flags it as unusual. For example, one could train a GAN on normal heartbeat sensor readings, then detect irregular heartbeats by seeing if the discriminator finds them “fake” (not like the training data).
- Entertainment and Media: The entertainment industry finds GANs useful for creating visual effects. Need to create a fantastical creature or de-age an actor in a movie? GAN-like models can help generate the frames or modify faces realistically. They have been used to create very life-like avatars and characters in video games and virtual reality – for instance, generating faces for non-playable characters that look unique and real. In music, while GANs are more common in images, there are analogous models (GANs for audio) that generate new music or voices. Some researchers have used GANs to generate short pieces of music or to create realistic speech (though other techniques like autoencoders and transformers are more common in audio).
- Translation between Modalities: Pushing boundaries, GANs are also used to translate between different data types. An example is text-to-image generation: models like StackGAN and others (preceding the current diffusion model trend) used a GAN-based approach to generate images from textual descriptions (e.g., “a bird with red wings and a short beak” → an image of such a bird). These models extend the conditional GAN idea to a language condition. While newer techniques have emerged, GANs laid groundwork in this area. Similarly, there have been experiments with image-to-sound (imagining what a scene might sound like) or sketch-to-image for design.
In summary, GANs are incredibly versatile. They can act as imaginative engines in any domain where examples can be learned. From improving the quality of our photos, to helping design products, to generating content for games and movies, to expanding datasets for AI training, GANs have found a place. And with ongoing research, new applications keep emerging. For instance, GANs are being explored in drug discovery (generating molecular structures with certain properties) and in materials science (proposing new material microstructures) – showing that their use isn’t limited to visuals. Whenever we need a creative partner AI that can produce realistic variations or wholly new candidates, GANs are often a go-to approach.
Challenges in Using GANs
Despite their successes, GANs come with a set of notorious challenges and limitations. Anyone who has tried to train a GAN (or even just understand the literature) will encounter these common hurdles:
- Training Instability: GANs are infamously difficult to train. The generator and discriminator have to be carefully balanced – if one learns too fast or too slow relative to the other, things can go awry. For example, if the discriminator becomes too good, it will always confidently reject the generator’s outputs, and the generator will get almost no useful feedback (a scenario called the generator’s loss saturating). On the flip side, if the generator somehow gets way better than the discriminator early on, the discriminator might be fooled all the time and provide no meaningful learning signal. This tug-of-war can lead to oscillations (where the GAN’s performance wildly swings and never settles) or divergence (where training fails completely, yielding nonsense outputs). Practically, training GANs often requires a lot of trial and error with hyperparameters, careful architecture design, and tricks like feature matching or loss function tweaks to keep the process on track. Even then, it’s not guaranteed to converge nicely. This instability is a core challenge – researchers liken it to finding a Nash equilibrium between the two players, which is mathematically difficult in high dimensions. Various improvements like WGAN (Wasserstein GAN) were proposed to make the training more stable by changing the loss function and other details, and while these help, GAN training remains something of an art.
- Mode Collapse: One persistent issue specific to generative models like GANs is mode collapse. This is when the generator, instead of learning to produce the full variety of data samples, collapses to producing only a few modes (types of outputs). In extreme cases, the generator might learn to produce essentially the same output (or a few variants of it) for every input noise – it has found a weakness in the discriminator that one particular kind of fake looks real enough, so it just exploits that and stops exploring other possibilities. For example, if a GAN is generating handwritten digits, it might collapse to generating the digit “1” over and over in different styles, ignoring the other nine digits. The discriminator sees lots of “1”s that look real and might still be somewhat fooled if those look like real “1”s, allowing the generator to get away with this. Mode collapse means loss of diversity – the GAN isn’t covering all the modes of the true data distribution. Partial mode collapse might mean, say, a face generator that produces faces with very similar facial structures or all with the same background. This is bad if we want a truly generative model capturing all the richness of the real data. Detecting mode collapse might involve noticing that outputs look too similar or statistical tests showing lack of variety. Mitigating it is tricky: techniques include using minibatch discrimination (so the discriminator can catch lack of diversity in a batch of outputs) or unrolling the optimization, among others. It’s an area of active tweaking when training GANs.
- Evaluation Difficulty: As we discussed in the evaluation section, measuring GAN output quality is not straightforward. Unlike predictive models, there isn’t a single clear metric. You might train a GAN and get a low FID, but does that mean your images are subjectively good? Or your FID might be okay, but perhaps the model is producing subtle errors a human would notice (like messed up text in images, or weird eyes on a face). Oftentimes, researchers and engineers have to rely on visual inspection – literally looking at many samples and judging quality, or conducting user studies – to be confident in a GAN’s performance. This makes GAN development somewhat slow and iterative: you tweak something, train for hours or days, then look at results and decide if it improved. Automated metrics help compare models, but they are imperfect proxies. Moreover, different applications might demand different definitions of “good” (artistic images have different criteria than medical images). So, evaluating GANs remains a challenge, and it’s hard to guarantee that one model is definitively better than another in all aspects just by a number. This challenge also connects back to the instability: because training can be unstable, you might run the same GAN training process twice and get slightly different results, and you’d need to evaluate both to pick the better one.
- Compute Requirements: GANs, especially the impressive ones like StyleGAN, can be computationally hungry. Training a GAN often requires powerful GPUs (or TPUs) and lots of memory. For example, generating high-res images means the neural networks are large and you need to process many details – StyleGAN2 for 1024px faces was trained on some heavy-duty hardware for days. Not everyone has access to such resources, which can limit who can experiment with or deploy GANs at scale. Even after training, generating images can be computationally intensive (though typically inference is faster than training). Additionally, because you may need to try many experiments (due to the instability and evaluation issues), you end up using a lot of compute cycles in the process of just finding a model that works well. This is a barrier, especially for students or small labs, to working on GAN research or applications. Efforts are being made to optimize GAN models and training (for instance, using techniques to make models more efficient or using transfer learning to fine-tune a pretrained GAN instead of training from scratch). But generally, cutting-edge GANs push the limits of memory and processing. The compute demand also raises the issue of energy consumption – large models have a carbon footprint, so efficiency is an increasing concern. In real-world deployment, if you wanted to run a GAN-based service (say, a website that generates art on the fly), you have to consider the cost of running those models on servers.
Apart from these main challenges, it’s worth mentioning a couple of others:
- Lack of Theoretical Understanding: GANs work well, but the theory lags behind practice. It’s not fully understood theoretically why certain tricks stabilize training or how to guarantee convergence. This is more of a research challenge, but it means improvements often come from trial-and-error rather than from first principles.
- Ethical and Misuse Concerns: While not a technical training issue, it’s a real-world challenge: GANs can generate very convincing fake media, which can be misused (as in deepfakes for misinformation or harassment). This has led to an arms race of GANs vs. detection algorithms. Ensuring GAN technology is used responsibly is an ongoing challenge for society. Developers of GANs need to be mindful of these implications.
Despite these challenges, the community has made steady progress. Every year, new techniques emerge to address instability or mode collapse (for example, newer normalization techniques, better loss functions like the hinge loss, etc.), and hardware gets faster. So, while GANs can be frustrating to work with at times, they are gradually becoming more robust and accessible as these challenges are tackled one by one.
Conclusion and Further Exploration
Generative Adversarial Networks have proven to be one of the most remarkable innovations in AI over recent years. They brought together the ideas of game theory and deep learning to create something like a sparring match in which both participants (networks) get stronger. The result is a system that can dream up new data – images, sounds, even basic texts – that often fools us into thinking it’s real. This capability has already had a profound impact on creative industries, scientific research, and technological tools, as we’ve discussed.
For students and enthusiasts, GANs are not only fascinating in theory but also a fun challenge in practice. If you’re learning about GANs now, don’t be discouraged by their quirks. Yes, training them can be finicky, and you might spend days tuning a model, but the payoff is seeing a machine create something new that didn’t exist before – that’s a magical feeling! With resources like open-source code and pre-trained models, you can experiment with GANs even on modest hardware (for example, try training a simple GAN on low-res images, or use a cloud service or Colab notebook for more power). There are also many pre-trained GAN models available that you can play with – generating faces, landscapes, art, etc. – to get a sense of what they can do.
As you explore further, you might encounter newer generative models like diffusion models (the kind behind some recent text-to-image generators). Each has its pros and cons. GANs remain highly relevant and are often faster at generation and can yield very sharp results, so understanding GANs gives you a strong foundation in generative modeling overall. Many concepts from GANs (like adversarial training) are spilling over into other areas of AI as well.
In the spirit of a personal blog aimed at learning: I encourage you to try building your own GAN on a dataset that interests you. It could be as simple as generating handwritten digits (a common beginner GAN project using the MNIST dataset) or perhaps generating abstract art. You’ll learn a lot by doing – you’ll witness mode collapse, you’ll see training blow up when a hyperparameter is off, and you’ll also get the thrill when it starts to produce halfway decent outputs. Each of those challenges from the previous section will make much more sense once you see them firsthand, and overcoming them even on a small scale is very rewarding.
Finally, keep an eye on the field. GANs are continually evolving, with researchers finding new tricks to make them better or to apply them in novel ways. Who knows – by diving in now, maybe you will contribute to the next breakthrough in GAN research or find a cool new application for them. The world of AI generative models is a vast playground for creativity and innovation.
In conclusion, GANs exemplify the combination of simple ideas leading to powerful outcomes: just two networks playing a game can lead to machines that imagine and create. They have their difficulties, but that also means there’s room for you to innovate and improve them. Whether you’re fascinated by the math, excited by the visuals, or curious about the ethics, GANs offer plenty to explore. So go ahead – experiment with GANs, join communities discussing them, and maybe teach your GAN to create something beautiful (or at least weird and interesting)! Happy learning and generating!