Explanation of the paper CURL: Contrastive Unsupervised Representations for Reinforcement Learning
Overview
This article explores CURL: Contrastive Unsupervised Representations for Reinforcement Learning, a method that improves sample efficiency in reinforcement learning (RL) by integrating contrastive self-supervised learning with standard model-free RL.
CURL aims to address the challenge of training RL agents directly from pixel observations, which traditionally requires large amounts of data. By leveraging contrastive learning, CURL enables RL models to extract meaningful representations from high-dimensional image inputs, significantly improving performance on tasks in the DeepMind Control Suite and Atari benchmarks.
This article is based on the scientific paper "CURL: Contrastive Unsupervised Representations for Reinforcement Learning", authored by Aravind Srinivas, Michael Laskin, and Pieter Abbeel in 2020. The full paper is available on arXiv: [Read the paper].
Introduction
Training reinforcement learning agents directly from pixel observations (images) is a hard task because it requires a lot of data and is less sample-efficient than learning from low-dimensional state features. The pixel inputs contain unnecessary information and high variability that the agent must overcome. However, if we're able to extract the essential state information from pixels, then an agent might learn from images as quickly as it would from compact state inputs. This insight has motivated research into representation learning for RL: by learning better representations, we can close the gap in sample efficiency between pixel-based and state-based learning.
CURL (Contrastive Unsupervised Representations for Reinforcement Learning) is an approach that addresses this issue by integrating contrastive self-supervised learning with standard model-free RL. The idea in CURL is to train a convolutional encoder that extracts high-level features from raw pixels using a contrastive learning objective, while simultaneously training an RL agent on top of those learned features. By doing so, CURL enforces the encoder to output useful representations of the environment, which significantly improves the data efficiency of the RL algorithm. Empirically, CURL outperforms previous pixel-based RL methods on challenging benchmarks – achieving nearly 1.9× higher performance on DeepMind Control Suite tasks and 1.2× higher on Atari games (measured at 100K interaction steps) compared to prior state-of-the-art methods. In the following, we will explain how CURL works, the contrastive learning principles behind it, and the experimental results that highlight its contributions.
Understanding Contrastive Learning in RL
Contrastive learning is a self-supervised technique where the model learns to differentiate between similar and dissimilar data points. The goal is to encode inputs so that representations of related inputs (positives) are close together, while unrelated inputs (negatives) are pushed apart. In practice, this means generating two different views of the same input (for example, two randomly augmented versions of the same image) and treating them as a positive pair, and other images in the batch are considered as negatives. The model, typically through a Siamese or twin-network architecture, is trained to maximize the agreement between the embeddings of the positive pair and minimize agreement with negatives. This objective drives the encoder to capture the input's underlying factors that remain unchanged despite applied transformations (cropping), typically representing semantic or task-relevant features.
How CURL Works
CURL's architecture integrates an RL agent with a contrastive representation learning module within a unified training loop. The visual encoder (a convolutional neural network) is shared between the two: its parameters are used to produce the features that go into the RL algorithm, and they are simultaneously updated by a contrastive loss objective.
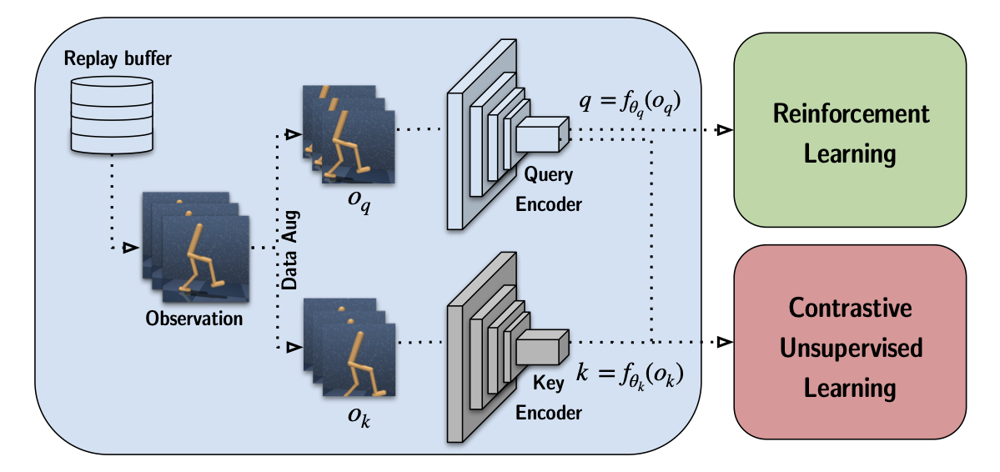
Figure: High-level architecture of CURL. An observation (typically a stack of consecutive image frames) is taken from the replay buffer and two randomly augmented versions of it are generated: one as the query image \(o_q\) and one as the key image \(o_k\). These are passed through two encoders: a query encoder (top) and a key encoder (bottom). The key encoder is a slow-moving momentum copy of the query encoder. Both encoders output latent representations (denoted \( q = f_{q}(o_q) \) and \( k = f_{k}(o_k) \)). The RL algorithm (e.g. SAC or DQN) uses the query encoder’s output \( q \) for its value/policy network, while a contrastive loss is applied between \( q \) and \( k \) to train the encoder to produce similar embeddings for the same observation (and dissimilar for different observations).
CURL employs the InfoNCE loss, a variant of Noise Contrastive Estimation, as its contrastive loss function. For a given anchor query \( q \), the positive key \( k^+ \) is the encoded representation of the same observation (through the momentum encoder), and negatives \( \{k^-\} \) are encoded representations of other different observations in the minibatch (or a memory).
\[ \mathcal{L}_q = \log \frac{\exp(q^T W k_+)}{\exp(q^T W k_+) + \sum_{i=0}^{K-1} \exp(q^T W k_i)} \]
The InfoNCE loss encourages \( q \cdot k^+ \) (similarity between query and its positive) to be higher than \( q \cdot k^- \) for all negatives. In practice, this can be framed as a classification task, where the model must identify the correct positive \( k^+ \) among a set of negative keys for each query.
Performance Analysis and Benchmarks
One of the most striking aspects of CURL is its strong performance on standard RL benchmarks when using pixel observations. The authors evaluated CURL on tasks from the DeepMind Control Suite (a set of continuous control environments with camera observations, such as Walker, Cartpole, Cheetah, etc.) and on Atari 2600 games (discrete action, classic games). They focused on the 100K interactions regime – meaning the agent is only allowed to interact with the environment for 100,000 steps, which is a fairly small amount for these challenging tasks. This setting tests the sample efficiency of the algorithm.
CURL’s results show large gains in this regime, compared to previous approaches.
CURL (paired with SAC) achieved a 1.9× higher median score across tasks than the previous state-of-the-art algorithm (which was a model-based method called Dreamer). In practical terms, where Dreamer or other prior methods might reach, say, 50% of a task’s maximum performance with 100K samples, CURL pushes that to approximately 95% (almost double).
More impressively, when looking at state-based SAC (i.e., an agent that gets privileged access to the true state variables instead of images), CURL’s pixel-based agent nearly matches its performance on the majority of the 16 tasks evaluated. This is a big deal – historically, there was always a significant gap between image-based and state-based RL performance, but CURL largely closed that gap on DMControl. It suggests that CURL’s learned representations capture almost all the useful information needed for control.
In fact, CURL is noted as the first image-based method to reach this level of parity with state-based learning on these benchmarks. These results held across a variety of tasks (like Walker Walk, Cartpole Swingup, Finger Spin, etc.), indicating the approach is quite general.
Compared to other pixel-based methods (both model-free and model-based), CURL outperformed all of them in this sample-limited regime. Model-based methods like Dreamer and PlaNet, which learn a world model, were surpassed, as well as other representation-learning approaches like SLAC or SAC+AE (which uses an autoencoder).
The consistent gains suggest that contrastive representation learning is indeed more effective for accelerating RL than prior auxiliary losses or predictive models in these domains.
Atari games are another popular test for data-efficient RL. CURL was combined with a modified Rainbow DQN (a value-based method) for this setting. It also delivered strong results, with a 1.2× higher median human-normalized score at 100K steps compared to the best previous result (from a model-based algorithm called SimPLe).
In terms of absolute performance, CURL often needed only 100K interactions (which corresponds to roughly 2 hours of gameplay) to achieve scores that other methods might only reach after 500K or more interactions. When compared to Efficient Rainbow (a tuned version of Rainbow for low-data regimes by van Hasselt et al., 2019), CURL improved on the scores of Rainbow in 19 out of the 26 games evaluated.
In some games, CURL’s agent even surpassed human performance within this 100K step limit, which underscores how effective the representation learning is – the agent can make the most out of limited experience. Notably, Atari games have very diverse visuals and dynamics, so achieving broad improvements there indicates CURL wasn’t just overfitting to one type of environment. By learning good representations of Atari frames (which include various sprites, backgrounds, etc.), CURL helped the DQN prioritize important features (like the positions of enemies or the ball in Pong) early in training.
It’s interesting to discuss why CURL achieves such high sample efficiency. The results hint that when the encoder is trained with the contrastive objective, it learns a representation where different frames that essentially depict the same situation (even if the pixels differ slightly) map to similar latent vectors. This makes the downstream RL task easier – the agent doesn’t need to see as many repeats of a scenario to generalize, because the encoder already generalizes across small visual variations.
In DMControl, for example, CURL’s random crop augmentation might show the walker robot in slightly different positions in the frame; the contrastive loss ensures those all map to a similar internal state, which means the SAC agent can learn the walking behavior without being confused by camera shifts.
Essentially, CURL squeezes more learning signal out of each environment step by supplementing the sparse reward feedback with a rich self-supervised learning signal. This synergy allows CURL to reach higher performance with fewer samples than methods that rely on reward alone or on less informative auxiliary tasks.
The near-match with state-based performance supports the hypothesis that if the essential state information is present in the pixels, a good representation learning approach can indeed extract it such that learning from pixels can be almost as fast as learning from state.
Another key takeaway from the experiments is the generality of CURL’s framework. Because it is algorithm-agnostic (you can pair it with SAC, DQN, etc.), it provides a versatile way to boost an existing RL method.
The code was open-sourced by the authors, and they emphasized the importance of reproducibility. CURL doesn’t require delicate tuning of many hyperparameters or architectural tricks, making it relatively easy for other researchers and practitioners to adopt.
The strong benchmark performance has made CURL a reference point for pixel-based RL going forward, and many subsequent works have built upon similar contrastive or augmentation-based ideas to further improve RL from pixels.
Conclusion
In conclusion, CURL stands out as a milestone that demonstrated how learning "what makes two observations alike or different" can be just as important as learning from reward signals alone. By giving RL agents the ability to form their own understanding of the visual world through contrastive learning, we end up with agents that learn faster and smarter. As RL continues to tackle problems with high-dimensional inputs, representation learning techniques like those in CURL will likely play an increasingly crucial role in building efficient and robust learning systems.